Introduction
Author
Contact info
MINERVA
To implement any Machine learning/Deep learning algorithm we need a better and bigger dataset of SPDX Licences. Due to the lack of dataset currently, all the 10 algorithms which have been tested on Atarashi are restricted to 59% accuracy. There exists no such dataset for open source licenses that could be added to the existing dataset.
Why do we need to create OSS Dataset -
-
IRREGULARITY IN THE SIZE OF LICENSE TEXTS - The license texts are of different sizes with huge differences in terms of keywords count. Longer license texts contain most of the unique keywords when compared against the uniqueness of keywords in the smaller license texts.
-
DIFFERENT THAN TRADITIONAL TEXT CORPORA - In licenses most of the tokens are similar and the keywords used can be found in almost all of them with a slight variation since they all are open-source licenses stating open source softwares and underlying permissions. These similarities in licenses make them tough to be differentiated by any traditional information retrieval algorithm.
So, the idea is to generate SPDX OSS license dataset using FOSSOLOGY NOMOS AGENT STRINGS.in REGEX and latest SPDX released Licenses. We can use an existing file as a baseline model for further manipulating and generating texts from those files.
What is that I am doing right now?
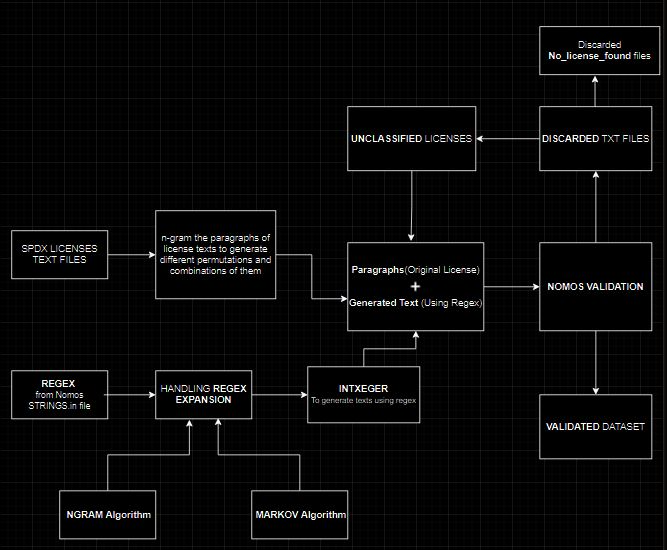
Till now, I have been able to fully automate the scripts to generate licenses using NLP algorithms and got them validated using Nomos. I have used "intxeger" for regex to text conversion and markov and n-gram algorithms for regex expansion and for initial splitting used Sliding window approach. Nomos can be used as a baseline to validate the generated texts.