Week 2
(June 10, 2025 - June 16, 2025)
Meeting 1
(June 11, 2025)
Attendees
Discussions
- Shared findings from a comprehensive analysis of the Minerva Dataset.
- Reviewed dataset characteristics like class imbalance, license frequency, and dataset composition by source.
- Talked about integrating negative samples into the dataset, which are currently missing but critical for training robust ML models.
- Presented a proof of concept for Locality Sensitive Hashing (LSH) and discussed its behavior with varying input lengths.
Minerva Dataset Analysis
Analyzed multiple dimensions of the Minerva dataset using visualizations. Key insights:
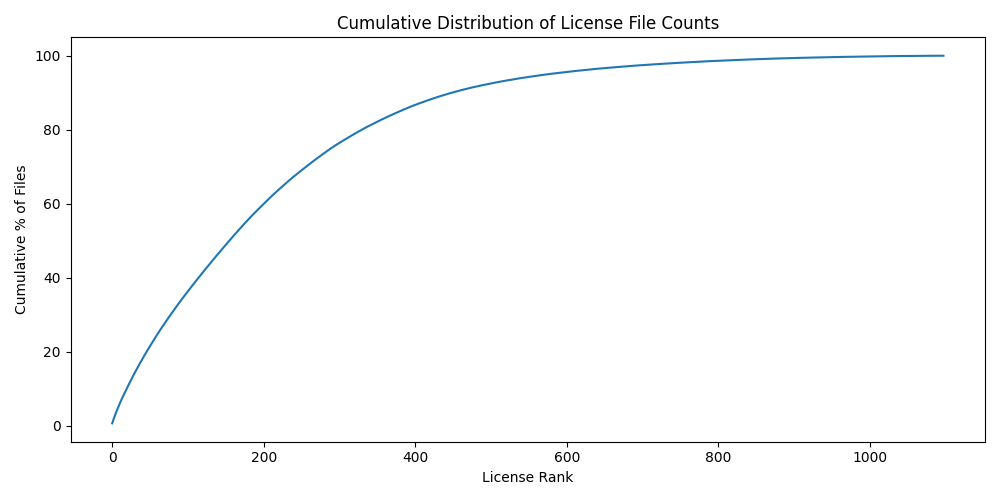
- Long-tail Distribution:
- The cumulative distribution shows that a small subset of licenses accounts for the majority of files.
- Around 200 licenses cover ~80% of the dataset, confirming a significant skew in class distribution.
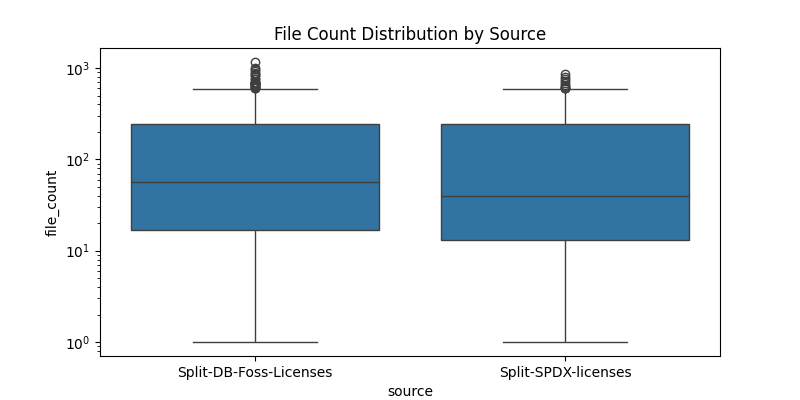
- Boxplots by Source:
- Both
Split-DB-Foss-LicensesandSplit-SPDX-licensesshow similar distributions, though the median file counts differ slightly. - Outliers are present in both, indicating a few licenses are over-represented.
- Both
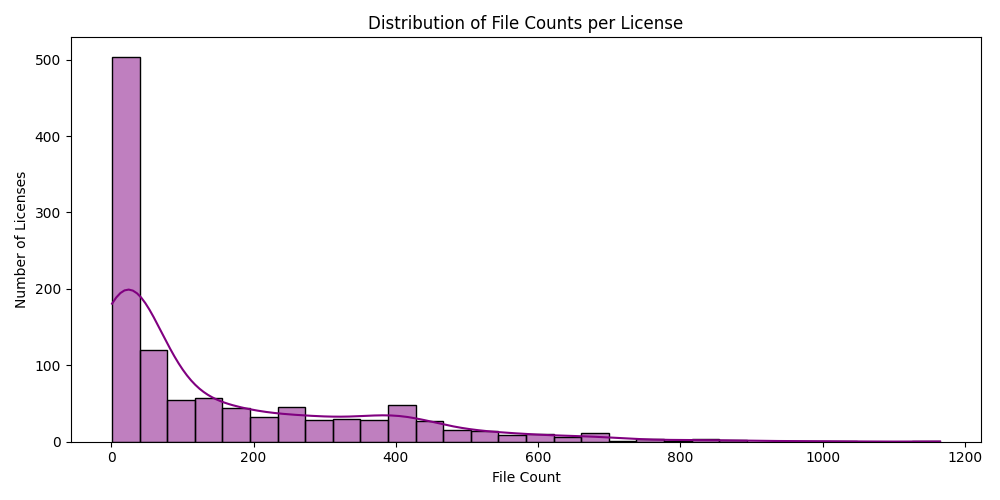
- Heavy Tail in File Counts:
- Histogram and KDE of file counts per license shows a large number of licenses with very few associated files, while only a few have 500+ files.
- This reveals severe class imbalance which can bias any learning model.
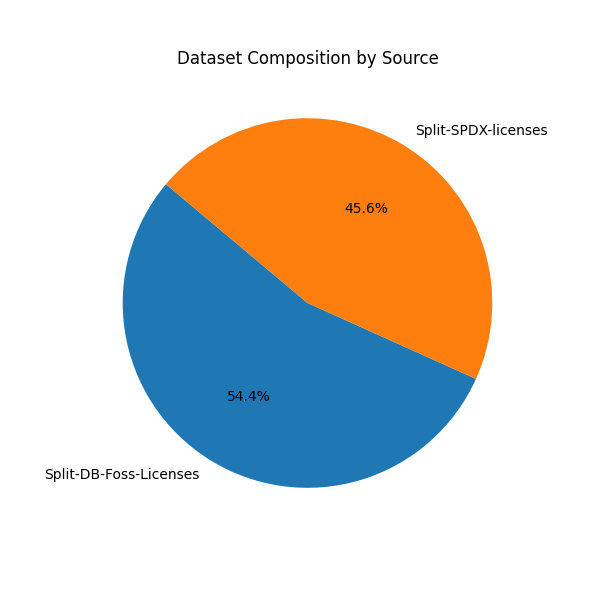
- Source Composition:
- The dataset is split nearly evenly: ~54% from
Split-DB-Foss-Licenses, ~46% fromSplit-SPDX-licenses.
- The dataset is split nearly evenly: ~54% from
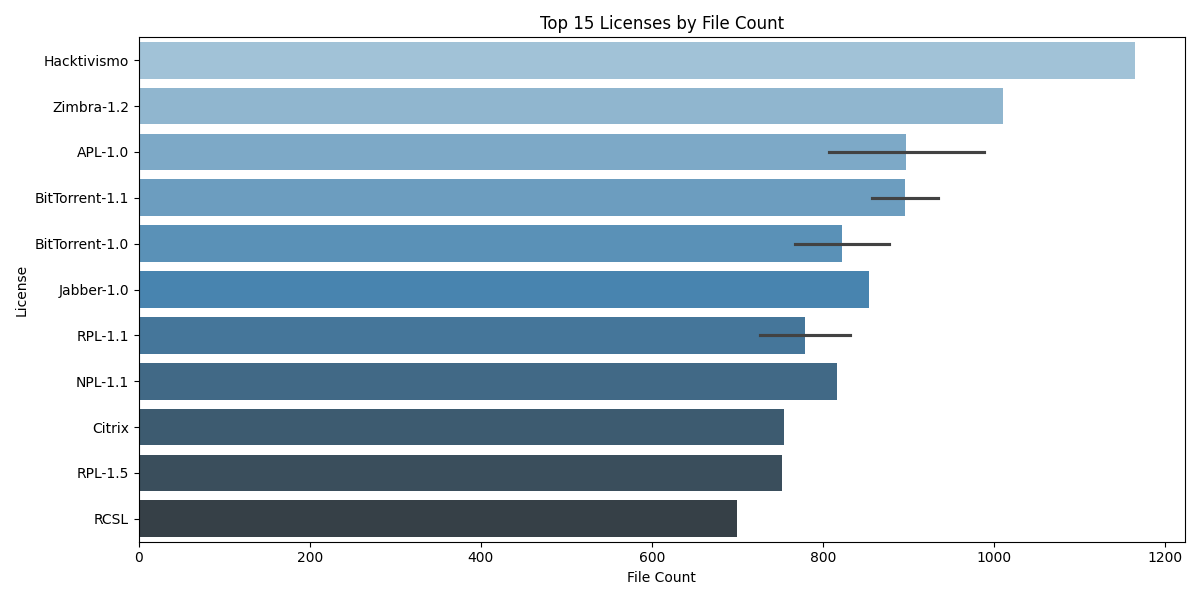
- Top 15 Licenses by File Count:
- Some licenses (e.g.,
Hacktivismo,Zimbra-1.2) dominate the dataset. - These must be considered while sampling or designing the pre-filtering ML models to avoid model bias.
- Some licenses (e.g.,
Updates
-
Spent time exploring and analyzing the Minerva Dataset.
-
Prepared and shared insightful visualizations for license frequency, source distribution, and class balance.
-
Identified key limitations:
- Severe data imbalance across license classes.
- Lack of negative samples — currently all samples are associated with known licenses, with no explicit “no license” or “non-license” examples.
-
Implemented a proof of concept for Locality Sensitive Hashing (LSH):
- Works well when input text length is similar to license texts.
- Struggles when input is shorter or a subquery, highlighting the need for preprocessing strategies or text padding.
Problems Identified
- Minerva lacks negative (non-license) samples, which will hinder the performance of classifiers in real-world noisy environments.
- LSH-based similarity is length-sensitive; needs improvement for partial or paraphrased inputs.
- Dataset imbalance could lead to model overfitting on high-frequency licenses.
Planning for Next Week
- Begin designing a dataset augmentation strategy to introduce negative samples.
- Study in more detail about Locality Sensitive Hashing.
- Experiment with segmenting license texts and input queries to better suit LSH-based techniques.
- Continue refining the dataset pipeline and class balancing.